


学院研究成果被人工智能领域顶级国际学术会议NeurIPS 2024录用发表
发布日期:2024-09-30 浏览次数:10
近日,全球最负盛名的人工智能学术会议之一NeurIPS’2024公布了录用论文,我校学院能源大数据智慧计算科研团队负责人杜海舟老师及其硕士生陈怡建撰写的《HyperPrism: An Adaptive Non-linear Aggregation Framework for Distributed Machine Learning over non-IID Data and Time-varying Communication Links》的分布式机器学习领域长文论文被NeurIPS 2024录用。
NeurIPS全称Annual Conference on Neural Information Processing Systems,在中国计算机学会,中国人工智能学会的推荐会议列表都中被列为A类会议,Core Conference Ranking推荐A*类会议,H5 index高达337,与ICML、ICLR并称为人工智能领域难度最大、水平最高、影响力最强的“三大会议”。NeurIPS 2024投稿量再创新高,共有15671篇有效投稿,接收率仅25.8%,将于2024年12月9日至15日在加拿大温哥华举行。这是上海电力大学首次作为第一单位在NeurIPS发表国际领先的学术研究成果,也是学院在CCF A类国际学术会议的突破性成果。这一研究成果取得标志着该团队在分布式机器学习领域取得了重大突破。
去中心化分布式机器学习(Decentralized Distributed Machine Learning)已成为大规模机器学习,尤其是大模型时代处理数据、模型训练、推理的重要范式。但在现实去中心化的应用场景(例如:自动驾驶,无人机群,电网无人巡检等)中充分利用多个分散设备来进行去中心化的机器学习和模型训练仍然具有挑战性,特别是基于传统线性聚合框架来解决全局机器学习模型收敛性是一个巨大的挑战,主要存在以下两个问题:非独立同分布数据异构性和时变通信链路问题。数据异构性是分布式机器学习训练的关键挑战之一,异构设备上非独立同分布数据的导致模型发散和收敛缓慢,并影响模型泛化性。随着时间动态变化的通信链路更是加剧了去中心化分布式机器学习训练过程的聚合难度,从而是每一轮的模型聚合具有很强的不确定性,从而导致整个模型训练收敛速度慢,甚至整个训练失败的情况。因此,有必要从全面的角度考虑数据异构性和时变通信链路,以提高去中心化分布式机器学习在现实世界中的应用性能。
为此,团队提出提出了一个非线性类聚合框架HyperPrism,它利用分布式镜像下降,在镜像下降对偶空间中进行聚合,并适应每轮使用的加权权重。此外,HyperPrism可以通过每个设备的专用超网络,自适应地选择本地模型不同层的不同镜像空间映射,实现高维度空间下去中心化分布式机器学习的自动优化。团队通过严格的数学分析和实验评估,证明了自适应镜像映射分布式机器学习的有效性。同时团队将结论泛化扩展到现有的模型线性聚合工作中,并将传统线性聚合方式变为HyperPrism中的一类特殊案例。
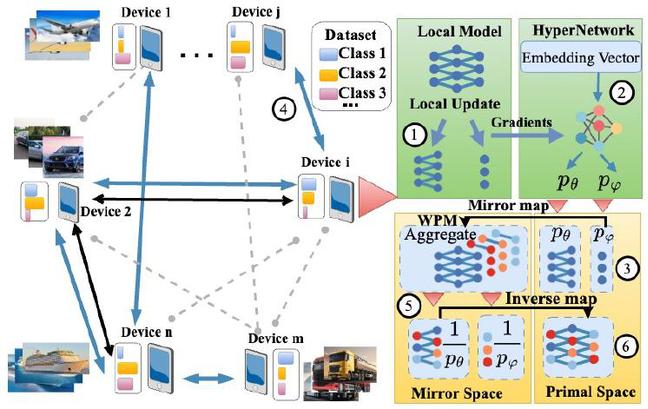
图1 HyperPrism框架整体架构概览
最后实验结果表明,与最先进的技术相比,HyperPrism可以将加速整个模型收敛速度提升98.63%,并且具有良好的模型可扩展性,可以很好地扩展到更多的设备,与传统的线性聚合相比,所有这些非线形聚合操作都没有增加额外的计算开销。这些成果都将对未来的基于车联网的自动驾驶,大规模电力无人巡检,大模型时代的模型分布式训练、推理应用产生重要影响,加速其应用落地。
该论文成果的其他合作者包括美国麻省理工学院和上海交通大学。该论文的发表代表了上海电力大学能源大数据智慧计算团队在分布式机器学习这一国际科技前沿领域的研究处于引领地位。
学院杜海舟 供稿